
Sejarah URL
Pada tahun 1991 merupakan tahun URL pertama kali ditemukan oleh Tim Barnes – Lee. Penemuan ini didasari oleh Tim Bernes-Lee dengan tujuan supaya dapat memudahkan para penulis dokumen atau artikel untuk mereferensikan tulisannya ke WWW (World Wide Web), itulah sejarah singkat mengenai URL.
Hingga pada akhirnya pada tahun 1994, Pengembangan terhadap URL terus dilakukan hingga menjadi URI (Uniform Resource Identifier) yang sifatnya lebih luas.
Apa Itu URL?
URL merupakan kepanjangan dari Uniform Resource Locator yang berarti suatu rangkaian karakter yang memiliki format dengan standar tertentu serta dapat digunakan untuk penunjuk alamat sebuah sumber yang ada di internet, baik itu berupa teks, gambar, dokumen, dan lain-lain.
Alamat URL dan Maksudnya

Seperti apa yang sudah dijelaskan di atas, terdapat berbagai bagian yang saling melengkapi dalam sebuah URL. Dibawah ini contoh URL dan maksudnya:
Contoh alamat URL:
https://kurikulumpgrikramatwatu.blogspot.com/p/mengenal-url-html-dan-search-engine.html
Maksudnya :
- Pertama, https merupakan protokol dan mempunyai kegunaan sebagai website di internet.
- Kedua, www merupakan sebuah nama host yang digunakan untuk mengenali dengan pastis sumber yang berguna dari situs yang ada di internet.
- Ketiga,kurikulumpgrikramatwatu.blogspot.com/ yaitu domain utama dari sebuah situs
- Keempat, mengenal-url-html-dan-search-engine.html merupakan nama file yang diakses di internet Nah, apa yang Kami paparkan di atas merupakan penjelasan singkat untuk Anda agar dapat mengenal URL beserta fungsinya.
Sejarah HTML
Pada awalnya mengenal HTML pertama kali diciptakan pada tahun 1989 oleh Tim Berners-Lee yaitu salah satu ahli fisika yang berada di lembaga penelitian CERN, Swiss. Saat itu HTML diciptakan untuk mengkodekan beberapa dokumen yang bersifat elektronik secara sederhana dan juga efektif.
Jika mengenal HTML lebih dalam, seperti yang sudah dijelaskan sebelumnya memiliki singkatan dari HypertText Markup Language, namun tahukah Anda apa saja arti dan juga penjelasan dari setiap kata tersebut?
Hypertext, merupakan metode yang berguna untuk berpindah satu halaman website ke halaman website lainnya dengan menggunakan text khusus pada internet yang disebut dengan hyperlink. Cara kerjanya text tersebut apabila Kita klik nantinya Kita akan diarahkan pada halaman website lainnya. Itulah mengapa disebut dengan hypertext.
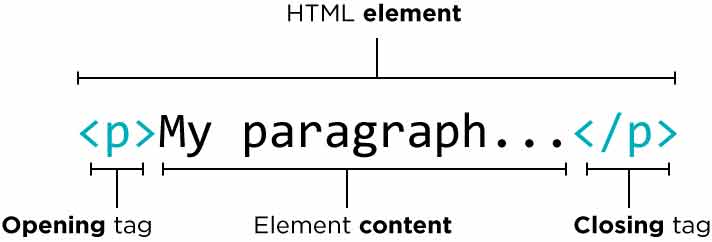
Markup, cukup terdengar unfamiliar bagi yang belum mengenal tentang HTML, nah Makup ini merupakan hal yang biasa dilakukan dalam tag HTML pada teks yang tersedia guna menandai tipe teks tertentu. Seperti contohnya terdapat tag atau tanda html <i> maka berarti teks dengan tanda tersebut akan berubah jadi italic atau berupa huruf miring, begitu juga contohnya dengan tag <b> berarti bold maka teks akan berubah menjadi tebal.
HTML dibuka dengan tag khusus dengan nama Opening Tag dan ditutup dengan Closing Tag yang disisipi tag penutup </b>. Namun terkadang juga ada kasus tag tidak mempunyai Opening tag dan Closing Tag sebagai Contoh tag Gambar <img Src=”UTL GAMBAR” />.
Contoh menerapan Struktur dasar dari HTML (Catatan Anda bisa memanfaatkan Tools dari https://www.w3schools.com/html/ untuk mengeksekusi dan melakukan prakter percobaan Kode HTML Anda) :
<!DOCTYPE html><html><head><title>Page Title</title></head><body>
<h1>This is a Heading</h1><p>This is a paragraph.</p></body>
</html>
Keterangan :
- <!DOCTYPE html> – Merupakan deklarasi dari type dokumen dari HTML tersebut
- <html></html> – Dikenal dengan element utamad dari HTML karena semua element berada di dalamnya.
- <head></head> – Element ini berfungsi untuk memasukkan suatu konten yang tidak dimunculkan namun tetap diakses pertama kali. Sangat cocok untuk meletakkan beberapa kode pemanggil baik itu JS, CSS dan lainnya. Konten lainnya seperti keyword, deskripsi, CSS, dll.
- <title></title> – Merupakan judul dari halaman website yang muncul pada bagian tab browser.
- <body></body> – Berisi konten yang ditampilkan pada browser ketika pengunjung mengakes halaman tersebut.
Mengenal Mesin Pencari (Search Engine)
Jika anda pengguna internet pasti tidak asing lagi dengan istilah search engine. Search engine disebut juga dengan mesin pencari, dimana sistem yang ada pada sistem tersebut diolah melalui satu atau sekelompok komputer yang berfungsi untuk melakukan pencarian data. Data yang ada pada mesin ini dikumpulkan oleh mereka melalui suatu metode tertentu, dan diambil dari seluruh server yang dapat mereka akses. Jika dilakukan pencarian melalui search engine ini, maka pencarian yang dilakukan sebenarnya adalah pada database yang telah terkumpul di dalam mesin tersebut. Jadi dapat di simpulkan Searh Engine adalah Mesin Pelacak atau penelusur.
Search engine adalah sistem database yang dirancang untuk mengindex alamat-alamat website di internet. Untuk melaksanakan tugasnya ini, search engine atau mesin pencari memiliki program khusus yang biasanya disebut spider crawler. Pada saat Anda mendaftarkan sebuah alamat website (URL), spider dari search engine tersebut akan menerima dan menganalisa URL tersebut lalu mengcrawlnya.
Dengan proses dan prosedur yang serba otomatis, spider ini akan memutuskan apakah web yang anda daftarkan layak diterima atau tidak pada search engine tersebut. Jika layak, spider akan langsung menambahkan alamat URL tersebut ke sistem database mereka. Rangking-pun segera ditetapkan dengan algoritma dan caranya masing-masing. Jika tidak layak, terpaksa Anda harus bersabar dan mengulangi pendaftaran diwaktu yang lain. Jadi semua yang namanya search engine, pasti memiliki program yang disebut Spider crawler. Dan program inilah yang sebenarnya menentukan posisi web site Anda di search engine tersebut.
Contoh beberapa search engine terkenal adalah : Altavista, Google, Excite, Northern Light, Hotbot, dan masih bayak lagi. Berbeda dengan web directory yang meng-index halaman website di internet secara manual. Manual yang dimaksud adalah mereka menggunakan orang biasa untuk menganalisa setiap halaman web yang masuk. Tidak menggunakan spider atau crawler seperti halnya search engine. Keunggulan directory dibanding search engine adalah memberikan hasil pencarian yang lebih relevan dengan kualitas yang relatif lebih baik. Tapi karena semua proses dilakukan secara manual (menggunakan editor manusia), jumlah database yang dimiliki biasanya jauh lebih kecil dibandingkan dengan search engine.










0 komentar:
Posting Komentar